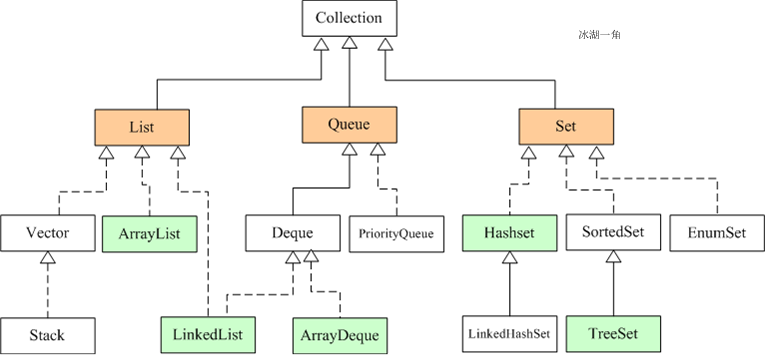
一.ArrayList、LinkedList 和 Vector 的区别。
1.ArrayList非线程安全的,Vector是线程安全的。
2.ArrayList扩容时按照50%增加,Vector按照100%增加。
3.ArrayList的性能要高于Vector
4.LinkedList是链表实现的,因此查询慢,增删快。
5.LinkedList提供了List接口没有提供的方法,方便数据的头尾操作。
二.快速失败 (fail-fast) 和安全失败 (fail-safe) 的区别是什么?
1.快速失败:如果用迭代器遍历集合时,如果集合内容发生了改变。这时会抛出一个ConcurrentModificationException.
2.安全失败:迭代器遍历时用的是原集合的拷贝,因此改变原集合不会引起一场,但是这样也就无法感知原集合的变化了。
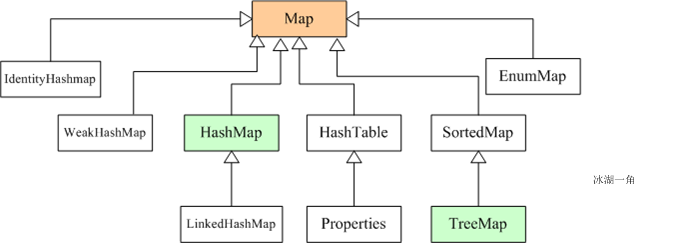
三.hashmap的数据结构
1.是由数组和链表/红黑树组成的,链表的数据多了就会转为红黑树。转换的阈值是8.
2.通过key的hashcode取模数组长度来确定将数据放到哪里
3.如果存放的位置已经有了数据了就形成链表向后放,node记录了next的节点。
4.默认初始容量是16,加载因子是0.75.意味着容量超过75%就会扩容一倍
5.key的equals用来确定在链表中是否有相同的key
四.List、Map、Set 三个接口,存取元素时,各有什么特点?
1.list可以有重复的元素,可以通过执行索引取元素,也可以在指定的位置存放元素
2.map键值对的方式存取元素,key不可以重复,可以通过key获取指定的键值对
3.set不允许存重复的元素,也就是equals相同的对象,也无法获取指定的元素。只能通过遍历。
五.两个对象值相同 (x.equals(y) == true),但却可有不同的 hash code,这句话对不对?
1.分不同的情况,如果对象的equals没有被重写的话,那么equals都是继承的Object的。即为==,也就是说equals相同证明了是同一个对象,hashcode也一定相同。
2.针对上面的这种规范,java倡导如果equals被重写了那么hashcode也要重写。以此来保证equals相同时hashcode也相同
3.而这个问题是对的,因为如果不遵守这个规范,当然equals相同hashcode可以不同了。
六.Java 集合类框架的基本接口有哪些?
add,addAll,clear,contains,containsAll,remove,removeAll
clear,containsKey,containsValue,get,put
七.HashSet 和 TreeSet 有什么区别?
1.HashSet是无序的,可以有一个null,非同步。TreeSet是有序的,不能有null,通过compare方法决定放置的位置。TreeSet有两种排序方法:自然排序、自定义排序
2.HashSet是通过哈希表实现的、TreeSet二叉树实现的
八.HashSet的底层实现是什么?
1.通过hashmap来实现的,用key来存储数据,保证key的唯一性
九.LinkedHashMap 的实现原理?
hashmap+双向链表实现的,是有序的,分为插入顺序和访问顺序。
十.为什么集合类没有实现 Cloneable 和 Serializable 接口?
应该有具体的实现来完由
十一.什么是迭代器?
为了方便容器的遍历,和具体的容器进行解耦。提供了公共的实现方法。
十二.Iterator 和 ListIterator 的区别是什么?
Iterator是一个接口,ListIterator是对它的具体实现
十三.数组 (Array) 和列表 (ArrayList) 有什么区别?
1.Array是定长的,ArrayList是变长的。
2.Array适合处理不变的数据,ArrayList提供的方法更丰富。
十四.集合使用
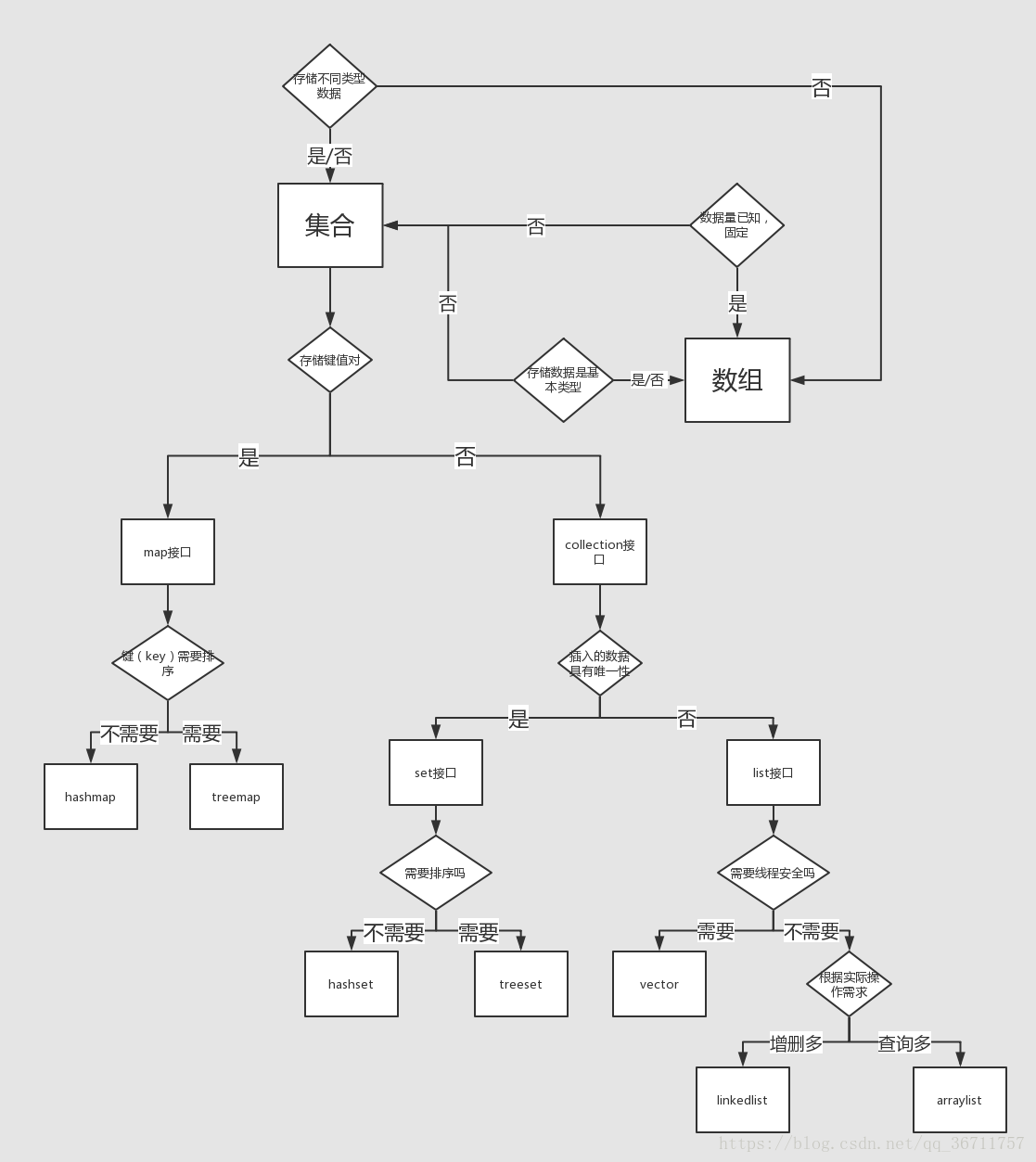
十五.Set 里的元素是不能重复的,那么用什么方法来区分重复与否呢?是用 == 还是 equals()?它们有何区别?
equals
十六.Comparable 和 Comparator 接口是干什么的?列出它们的区别?
如果想对一个对象进行排序,可以有两种方式。一个是这个对象实现comparable接口、另一个是单独写一个类,这个类实现Comprator接口。相当于一个在需要排序的内部实现,一个可以在外部实现。
十七.Collection 和 Collections 的区别。
Collection是集合的接口、Collections是操作集合的一个工具类
十八.java类加载过程?
1.加载->链接(验证、准备、解析)->初始化
2.加载:加载二进制流、静态结构转化为方法区和数据结构、生成类对象
十九.jvm加载class的原理和机制?
1.java通过双亲委派机制加载类,这样的好处是安全。
2.有三个类加载器:系统类加载器(加载java的系统类)扩展类加载器(继承和实现的类)程序类加载器(程序员自定义的类)
二十.java内存分配?
堆:存储java的实例对象
栈:线程私有,存储局部变量表,动态链接
方法区:线程共享的,存储class二级制文件。包含类信息、常量池、静态变量
程序计数器:线程私有的,记录着程序运行的位置
本地方法栈:存储java本地方法信息
二十一.GC是什么?
是java的内存回收机制,通过算法判断对象是否为垃圾对象来进行回收。如果判断对象是垃圾对象呢,有两种算法:一种是引用计数法,当对象被引用一次时计数加一。当引用计数的次数为零的时候就表示对象无用了。但是这种算法有一个问题,就是当对象循环引用时无法做出正确的判断。还有一种算法是可达性分析:把对象看作一棵树,看对象是否可达。
回收过程:1.分为下面四个区:eden、s1、s2、old
2.对象先放入eden中,满了就放入s1-》s1满了放入s2,eden和s1清空-》s2满了将对象放入old中,然后s1和s2互换-》old满了进行老年代的回收
二十二.Java 中会存在内存泄漏吗
数据库连接、网络连接
二十三.深拷贝和浅拷贝
深拷贝是拷贝对象的属性,如果原对象有引用的属性则修改引用属性不会引起拷贝对象的变化。
二十四.System.gc和Runtime.gc
功能一样,不建议使用。
二十五.finalize() 方法什么时候被调用?析构函数 (finalization) 的目的是什么?
对象回收前会调用finalize方法、析构函数与构造函数相反,就是释放资源。
二十六.什么是分布式垃圾回收(DGC)?它是如何工作的?
跨虚拟机的远程对象引用,引用有租期。定时发送租约。
二十七.串行(serial)收集器和吞吐量(throughput)收集器的区别是什么?
串行针对小应用、吞吐量针对大数据量
二十八.Minor GC 和 Major GC
minorGC是新生代的gc、Major是老年代的gc
二十九.JVM 的永久代中会发生垃圾回收么?
不会,如果满了会直接抛出异常。
三十.双亲委派机制?
会递归它的父类加载器进行加载,好处:放置重复加载、安全。
三十一.Synchronized 用过吗,其原理是什么?
重量解锁,可以修饰方法,也可以修饰代码块。是通过监视器实现的。一个监视器的锁只能被一个线程持有,这样保证了同一时刻只有一个线程执行这段代码。进入监视器时enter、退出时exit、并且监视器有一个计数器。这个线程获得了这个锁计数器就加一,同一个线程再次获得这个锁时就再加一。最后这个计数器为零时表明其他线程可以访问这段代码了。
三十二.什么是可重入性?
如果当前线程持有了这个锁,那么再有这个锁的同步方法或代码块时这个线程可以再次进入。
三十三.jvm队员是所做了哪些优化?
分为偏向锁(单线程访问的场景,加锁解锁速度快)、轻量级锁(多线程执行时的执行速度很快的场景,会进行自旋,效率更高)、重量级锁
三十四.锁消除和锁粗化?
锁消除:jvm在编译器会对代码进行是否可逃逸分析,发现同步的代码不可以不其他线程访问到就会进行锁消除。
锁粗化:就是看同步块之间没有同步的代码执行的速度是否快,如果未同步的代码执行速度很快。那么可以将两个同步代码合为一个,这样同一个线程减少了申请锁的次数,提升了效率。
三十五.乐观锁、cas?
乐观锁:乐观地认为并发的问题实属罕见,通过version来控制并发修改的问题。每次修改version都会加一,如果当前请求是获取version与最后提交时的version不同表明发生了并发问题,会更新失败。
cas:compare and swap 比较值和预期值作对比,如果相同就进行更新。但是会出现ABA问题。
三十六.ReentrantLock原理?
是通过cas和队列实现的,先通过cas获取锁的状态-》state为零且队列为空时当前线程得到锁、state不为零时将当前线程放入队列中进行排队-》持有锁线程释放锁,判断是否为公平锁。如果是公平锁,那么队列头的线程获得锁。如果是非公平锁,那么队列中的线程都有可能获得锁。
三十七.AQS?
队列同步器
三十八.请尽可能详尽地对比下 Synchronized 和 ReentrantLock 的异同。
1.ReentrantLock有公平锁和非公平锁
2.ReentrantLock可以终止等待
3.ReentrantLock可以分组唤醒
4.Synchronized使用起来更便捷,ReentrantLock功能更多,带需要手动释放锁。
三十九.ReentrantLock 是如何实现可重入性的?
获得锁的线程再次进入同步块的时候state会加一,释放锁的时候回减一。
四十.ReadWriteLock 和 StampedLock
ReadWriteLock:读写锁,允许多线程并发读操作。StampedLock:相对于ReadWriteLock的一个优化,ReadWriteLock并发读线程回阻塞写线程。而StampedLock则不会。
四十一.如何让 Java 的线程彼此同步?
wait、notify、park、unpark
四十二.CyclicBarrier 和 CountDownLatch区别?
CyclicBarrier:控制并发进入的现成的数量 CountDownLatch:减数器,主线程可以阻塞等待,知道减数器为零。
四十三.线程池实现原理?

四十四.线程池核心的构造参数?
corePoolSize:核心线程数
maximumPoolSize:最大线程数
keepAlivesTimes:非核心线程存活时间
workQueue:等待队列
handler:拒绝策略
四十五.如何在 Java 线程池中提交线程?
execute:无法获取返回值、submit:可以通过futureTask获取返回值
四十六.既然提到可以通过配置不同参数创建出不同的线程池,那么 Java 中默认实现好的线程池又有哪些呢?请比较它们的异同
newFixedThreadPool:指定数量的线程池,核心线程数和最大线程数一样。
newCachedThreadPool:缓存线程池,核心线程数为零,但最大线程数是Integer.MAX_VALUE,线程存活时间为60s。
newSingleThreadExecutor:核心线程数和最大线程数都是一个线程,保证任务的顺序执行。
四十七.Java 中各个线程是怎么彼此看到对方的变量的?
四十八.请谈谈 volatile 有什么特点,为什么它能保证变量对所有线程的可见性?
可以保证可见性,不能保证原子操作,如i++
四十九.请对比下 volatile 对比 Synchronized 的异同。
1.volatile是轻量级的
2.多线程并发访问volatile不会阻塞
3.volatile只保证可见性,不能保证原子操作
五十.ThreadLocal 是怎么解决并发安全的?
每个线程存储的是本地变量副本,没有共享数据。线程当然安全了。但是线程中是无法获取到在主线程中设置的ThreadLocal的值的。他的一个子类可以。
五十一.什么是spring,有哪些模块?
java框架,模块包括spring core、spring web、spring mvc、spring context、spring dao、spring orm、spring dao
五十二.使用spring框架带来哪些好处?
解耦、aop、声明式事务、对其他框架开放、
五十三.BeanFactory 和 ApplicationContext 有什么区别?
ApplicationContext继承自BeanFactory,前者丰富了很多功能。如:国际化、aop、加载上下文… 并且Application是对于bean预加载的,而BeanFactory是懒加载的。
五十四.spring有几种配置方式?
xml、注解、java类
xml:<bean id=”userDao” class=”cn.lovepi.***.userDao”/>
注解: @Component(“userDao”)
public class userDao{……}
java:使用@Configuration注解需要作为配置的类,表示该类将定义Bean的元数据,使用@Bean注解相应的方法,该方法名默认就是Bean的名称,该方法返回值就是Bean的对象。
五十五.springBean生命周期?
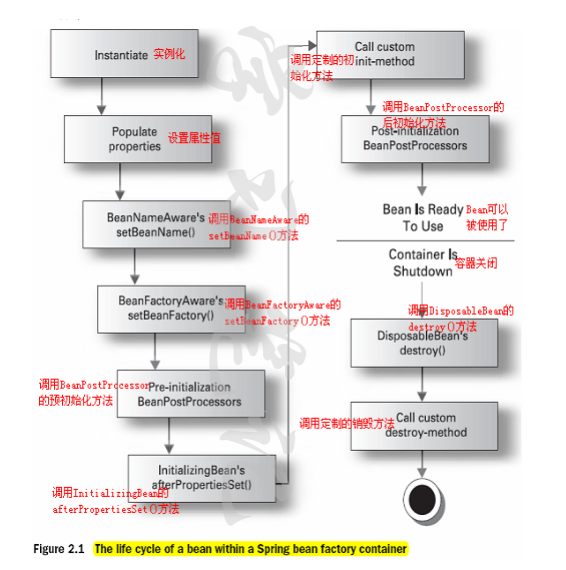
创建-》初始化-》使用-》销毁
五十六.Spring bean元素的作用域?
- 当通过Spring容器创建一个Bean实例的时候,不仅可以完成bean实例的实力化,还可以为bean指定作用域。Spring bean元素的支持以下5种作用域:
- Singleton:单例模式,在整个spring IOC容器中,使用singleton定义的bean将只有一个实例。
- Prototype:多例模式,每次通过容器中的getBean方法获取prototype定义的beans时,都会产生一个新的bean的实例。
- Request:对于每次Http请求,使用request定义的bean都会产生一个新的实例,只有在web应用时候,该作用域才会有效。
- Session:对于每次Http Session,使用session定义的Bean都将产生一个新的实例。
- Globalsession:每个全局的Http Sesisonn,使用session定义的本都将产生一个新的实例。
五十七.spring inner beans?
在bean中声明另一个bean作为属性
五十八.spring中的bean是线程成安全的吗?
- Spring框架并没有对单例的bean进行多线程的封装处理,线程安全问题和并发问题,需要我们开发者自己考虑。
- 但实际上,大部分的Spring bean并没有可变的状态(比如:service类和dao类),所有在某种程度上来说Spring单例bean是线程安全的。如果bean有多种状态的话(比如:View Model对象),就需要自行考虑线程安全问题。
五十九.什么是自动装配?
- 就是将一个Bean注入到其它的Bean的Property中,默认情况下,容器不会自动装配,需要我们手动设定。Spring 可以通过向Bean Factory中注入的方式来搞定bean之间的依赖关系,达到自动装配的目的。
- 自动装配建议少用,如果要使用,建议使用ByName
六十.@Required
@Required 注释应用于 bean 属性的 setter 方法,它表明受影响的 bean 属性在配置时必须放在 XML 配置文件中,否则容器就会抛出一个 BeanInitializationException 异常。
六十一.autowired和resource?
1.@Autowired与@Resource都可以用来装配bean. 都可以写在字段上,或写在setter方法上。
2.@Autowired默认按类型装配(这个注解是属业spring的),默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,如:@Autowired(required=false) ,如果我们想使用名称装配可以结合@Qualifier注解进行使用
六十二.构造方法注入和设值注入有什么区别?
- 设值注入写法直观便于理解,使各种关系清晰明了。
- 设值注入可以避免因复杂的依赖实例化时所造成的性能问题。
- 设值注入的灵活性较强。
- 构造方法注入可以决定依赖关系的注入顺序,有限依赖的优先注入。
- 对于依赖关系无需变化的Bean,构造方法注入使所有的依赖关系全部在构造器内设定,可避免后续代码对依赖关系的破坏。
- 构造方法注入中只有组建的创建者才能改变组建的依赖关系,更符合高内聚原则。
六十三.Spring 框架中有哪些不同类型的事件?
上下文更新事件(ContextRefreshedEvent):该事件会在ApplicationContext被初始化或者更新时发布。也可以在调用ConfigurableApplicationContext 接口中的refresh()方法时被触发。
上下文开始事件(ContextStartedEvent):当容器调用ConfigurableApplicationContext的Start()方法开始/重新开始容器时触发该事件。
上下文停止事件(ContextStoppedEvent):当容器调用ConfigurableApplicationContext的Stop()方法停止容器时触发该事件。
上下文关闭事件(ContextClosedEvent):当ApplicationContext被关闭时触发该事件。容器被关闭时,其管理的所有单例Bean都被销毁。
请求处理事件(RequestHandledEvent):在Web应用中,当一个http请求(request)结束触发该事件。
六十四.FileSystemResource 和 ClassPathResource 有何区别?
ClassPathResource在环境变量中读取配置文件,FileSystemResource在配置文件中读取配置文件。
六十五.Spring 框架中都用到了哪些设计模式?
单例模式、工厂模式、模板方法、代理模式、观察者模式…
六十六.设计模式应用场景
组合模式:针对树形结构
评论(0)